
Abstract
While a lot of effort has been deployed to computer languages since 60 years, surprisingly very little effort has been dedicated to the writing of computer programms. Although numerous program editors exist, that ease the process of effective writing, the appearance of (non data flow) programms has basically not changed since the punched cards. Basically computer programms are hard to read. This leads to numerous difficulties and high costs for writing, debugging and maintenance.
We study how humanity expressed knowledge based on semiotics, human cognition. We show a lack of expressiveness in the presentation of computer languages, which are essentially linearly written.
We propose here a novel 2D graphical approach named SGH schemes to writing programms, which present a lot of advantages, and especially improve on readability and expressive power. The approach is to use Non Linear Graphical Writing systems are more powerful to express knowledge.
The approach is very generic as a single but generic editor allows to produce any target languages as well as documents.
1. Introduction
While a lot of effort has been deployed to invent computer languages since 60 years, surprisingly very little effort has been dedicated to the effective writing of computer programms. Although numerous program editors exist, that ease the process of effective writing, the appearance of (non data flow) programms has basically not changed since the punched cards.Basically computer programms are hard to read. This leads to numerous difficulties and high costs for writing, debugging and maintenance.
We propose here a novel approach to writing programms, based on semiotics, human cognition, non linear 2D writing, which present a lot of advantages, and especially improve on readability and expressive power. The approach is very generic as a single editor allows to produce several target languages as well as documents.
The paper is organized in the following way :
- Context and motivation
- What is a language ?
- Presentation of SGH schemes suivi détaillé de chaque réunion
- Conclusion
2. Context and Motivation
The origin of this question is from knowledge representation systems.A seemingly very simple question brought unexpected difficulties : why can't we write computer programms in a mathematical and readable way ?
A very simple example shows the differences :
|
traditonnal computer programm
|
Mathematics 1
|
Mathematics 2
|
Mathematics 3
|
|
|
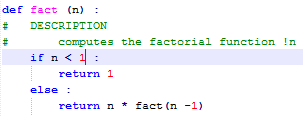
Factorial function what to notice |
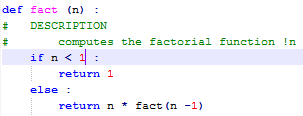 2 levels of languages : python and english for documentation mostly ascii documentation is a second class citizen. |
 inverted logic definition for 'if' and '!', only visual separation of cases, implicit factorisation of the definition. |
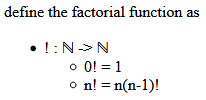 special character ℕ implicit integer multiplication, definition by pattern matching. implicit recursion |
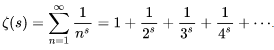 The Riemann function implicit infinite sum 2D notations small, large and special symbols, etc |
Going further, every time we open a math or physics textbook, we see a mix of mathematical formulas and explanations in natural language.
The mix of languages we observe with computer programs is not specific to computers, but also to all technical documentation.
2.1. Coexistence of several languages in documentation
The coexistence of several levels for messages and languages also exists in classical documentation. Typically, if we write a paper, we would like to keep in the original document traces of our thought process, of the structure of the paper, of sources, even if they don't appear in the final paper. For example, an audit of a company will produce some documentation, but will not provide everything that has been read, while the tracability of decisions and of the process must be ensured.Examples of what we could capture
- The underlying structure of the paper.
- The purpose of a specific paragraph.
- Some open questions at the time of writing : 'Needs to check this or that...'
- Some comments for future use.
Our final question is now : what kind of editor is needed to write correctly a computer program or general documentation, that allows to mix several messages and languages in one single editor ?
3. A language as a set of notations
3.1. What is a language ?
There are huge differences on what a language is according to the specialists of various fields.- Computer scientists : A computer language is a linear set of characters that should be interpreted by a computer to specify the computing. Most languages allow the linear set to be split into lines, and each line can contain a part of human readable text. The first step of processing is to remove the human part, and then process linearly the remaining characters. Most languages (except notably Python) don't use indentation as a specific indication of the structure of the program.
- Typographs : Some examples here how the wide variety of writings. Typographs are deeply convinced that the appearance of letters and words is very important for the understanding of documents. Bold, italics, letter size, etc. are frequently used to ease the understanding of texts. These graphical features allow the construction of the understanding by the reader.
-
Encyclopedists :
The encyclopedists from many countries struggled with the representation of knowledge.
Aside from the writing and story telling about things, encyclopedists quickly realized :
- The importance of graphics : The invention of ISOTYPES in 1920 by Otto Neurath and Gerd Arntz. We are now very familiar with these little and standardized drawings, which are also now part of the icon zoo.
- The invention of textual links by Diderot, which are now called hyperlinks in computerized documents.
- Linguists : Language is an oral communication tool for human tribes. The oral languages can be encoded through letters (alphabet based writing), syllabs (korean) and glyphs (egyptian, chinese), that are independant of the sound. It is mandatory to note that the linear structure of the oral discours (subject to time constraint), will be also represented linearly in these codings (horizontally or vertically). However, the rhythm of the living speech, silences and pitch, emphasis on words, etc are not well captured into written systems. Music uses a specific and precise notation system for rhythm, and parallelism of instruments, but which cannot be used easily in texts. On the far end of human writing, we find the written language Nsibidi (used in Africa for centuries) which tells stories in a 2D layout.
- Engineers and scientists : Language is a communication tool that must allow concise presentation of complex things. The standard notations for the oral language is extended to provide adequate representations of the studied objects : graphs are a very common tool to depict the interactions of objects.
- Semioticians : Semioticians have studied for a long time the relationship between content and expression. They distinguish clearly the meaning from its expression.
|
From various writing systems |
Nsibidi
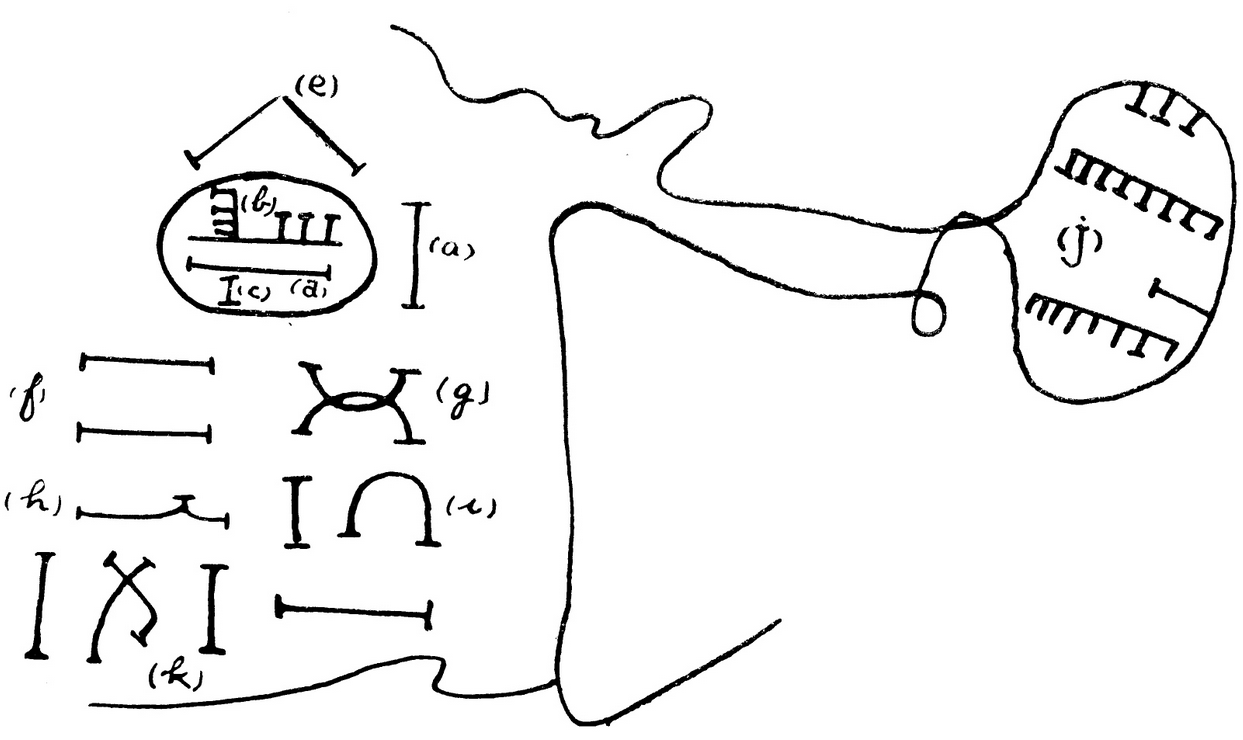
|
ISOTYPES

|
Typographs

|
Linguist
This is a sentence in english, written with the latin set of characters. |
|
to various meanings |
Mathematics
|
Computer program
|
Physics
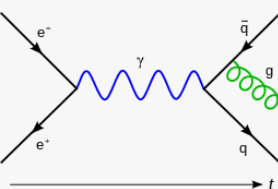
|
Music

|
At the end, we acknowledge that the writing systems are extremely varied, not only because of language, but also because of meaning : the efficiency of a writing system is that of the coding schemes that are used as much as they are related in a simple bijection to the external meaning. Coding schemes have to be efficient (compact) and meaningful (bijective and easy to understand). In fact, the possibilities of communication are extremely large :
- choice of coding : latin vs greek, vs chinese vs korean
- spatial encoding : left-to-right or contrary, vertical, 2D (nsibidi)
- use of special and aggregated symbols which all have their own and specific notation systems.
- existence of typography for readability : bold, italics, and icons.
From the work of typographs, we also know that readability is highly correlated to appearance. Readability is necessary at several levels for programming :
3.2. Several levels of languages in one document
The issue of writing multilingual documents has been already addressed extensively. Notably, the possibility of use many alphabets and directions of writing is addressed in the unicode/ ISO norm 10646. On a higher level, writing equations and mathematical texts and graphics is addressed by the Latex Language.However, what we want to capture is the several different levels of meanings in a single document. because we observe the coexistence of several languages
- target language
- explanation
- justification
- capture the design and thinking process
3.3. What is a computer programm ?
The usual definition of a computer program as " collection of instructions that perform a specific task when executed by a computer" falls short in several ways :- The language that is used must be precised : machine code is directly executable, while high level languages, which are human-readable, need to be translated. More in detail, we can also say that assembly code printed on paper is not executable : it need to be translated into bits and inserted into the machine to be executable. On the other side of the abstraction scale, an algorithm is independent of the programming language, requires some mathematical notations with a 2D layout, used often for indices, but not only. A particular class of programs, ie dataflow based, use a notation language which is the drawing of a graph, where each node represents a particular treatment of data by the machine. At this point, the question of what kind of notation is needed for describing a program to the machine arises.
- A programm is not dedicated only to the machine : it must be human-readable, and mostly understandable. Comments and documentation are a profound hint that computer programs are not easily understood and read by humans. They are necessary from the beginning, with the need to describe the purpose of the programs, and their details, to the maintenance phase, when the programs need to evolve. Documentation is also necessary to provide information and knowledge about the computer code : real world semantics, when it was designed, written, checked, if there is a proof of correctness, choices of implementation, etc.
- The documentation about a program must tell things about the environment : what it is related to, what are some architectures choices, etc.
In fact, a computer program is an aggregation of several messages, each dedicated to a targeted audience : the computer, the programmer, quality control, etc. Each message has it's own language, and all messages are intertwined in the programm. It is sad to see, with so much to say about programms, that tools for writing documentation like Word or Powerpoint are today highly uncompatible with programming !
One basic question is how should be mix these messages and languages to provide also the best document for humans ?
Computer scientists have spent a huge effort developing languages with many features :
-
Semantic content
A lot of effort has been dedicated to define the most general language, with many incompatible chapels (functional vs object programming, typed and untyped languages, etc), while dedicated languages exist for specific cases (ex : Esterel for synchronized real-time programming).
The work is done in two steps :
- define a theoretical framework.
- define the syntax of the language
-
Syntactic features
They appear on 2 levels :
- character Most computer languages know only the ascii characters. Some languages allow the wider use of ANSI/UTF8 standards. In its basic design, the APL functional language used all the greek alphabet to define its operators.
- words many computer make an heavy use of delimiting strings like 'begin'/'end' or '{'/'}' to specify and separate statements.
Despite the apparent sophistication of many modern IDEs (Integrated Development Environment), the underlying basic concept has not evolved since the punched card : a programm and its documentation are just an ordered collection of lines of text.
4. Presentation of SGH schemes
4.1. Introduction to SGH schemes
SGH schemes were developed initially as a Non Linear Writing System (as opposed to the linear sequential traditional writing mode. SGH stands for Scripto Graphic with Hyperlinks. SGH documents are organized in pages, each page being a SGH scheme.SGH schemes are basically 2D layouts of graphs, where nodes can exhibit many properties like text, graphics, icons, hyperlinks, etc.
- Hyperlinks can also adress directly nodes in the same document or across documents.
- Tables are also part of the SGH schemes, while boxes in tables are themselves a SGH scheme.
- Trees are SGH schemes, but have a special status, because their structure allows semantic representations (decomposition), spatial representations in relationship with their content (order of nodes), and allow visual manipulation (show/hide subtrees).
- SGH schemes are basically designed to be drawn and used with a computer.
- SGH schemes embed links
- SGH schemes allow tables
4.2. Some advantages of SGH schemes
SGH schemes are very easy to understand. In fact, it is much easier to produce a SGH scheme than a complex sentence or text. Just remember the long hours spent at school to write essays, while writing diagrams can be done in elementary school.SGH schemes are a good tool to represent knowledge. Trees are an ideal tool for decomposing thoughts, objects, while more general graphs allow the description of more complex structures or references. Also the
Compactness The use of visual patterns allows to synthesise in one small picture a whole idea about something. When representing knowledge about things, experiments have shown that the SGH scheme allow a reduction in the number of characters used up to 70%.
4.3. from 2D spatial writing to linearity
The main difficulty in using the SGH schemes is to go back to the traditional linear writing systems. Trees provide at least 2 linearisation possibilities : breadth-first of depth-first visit of nodes.The following table explicits the differences :
| Feature | SGH schemes | Traditionnal |
|---|---|---|
| >=2 languages |
free
|
reduced
|
| documentation inside the documentation |
yes
|
no or difficult
|
| Capture the design process |
yes
|
no
|
| capture the thinking process |
yes
|
no
|
4.4. Relation with syntactic editors
Syntactic editors for computer languages are known for a long time. They allow the automatic indentation and coloring of nodes, and even some immediate and simple transformations of programms. However they do not capture the different levels of meanings in the documentation : the final output vs the thought process that leads to it.What we are looking for with the SGH schemes is to define a very general tool for expressing thought with applications to documentation and programming.
5. Use of SGH schemes
Because the representation of SGH documents is very general, it is also very powerful, and allows to do easily complex actions and also more actions that were not previously possible.5.1. Capturing the thinking and design processes
 SGH schemes embed by design the notion of decomposition of thought and things, while the traditional oral and written need to use a lot of words to describe these decompositions.
For example, the decomposition of a problem in sub-problems is a common thought process.
SGH schemes embed by design the notion of decomposition of thought and things, while the traditional oral and written need to use a lot of words to describe these decompositions.
For example, the decomposition of a problem in sub-problems is a common thought process.
The graphic structure does not need any additional description.
The image below shows how the design of the above paragraph is self-explanatory :

SGH schemes can also have richer representation possibilities like tables (with SGH in the boxes), notably since tables are a well-established way of representing knowledge.
5.1.1. SGH schemes solve partly the 'context' problem.
The tree structure of documents provides an interesting approach to the notion of context : the context of a node is given as the path to the root (list on node names).5.2. Producing usual documents
Standard documents (computer languages -python C, ...- or human - html, doc, etc) are defined as the output of a SGH document by a SGH translator. The great advantage of SGH documents is that the processor are :- built-in difference between several languages and level of languages.
- ease of extensions
- capability to define macros.
5.2.1. Macros and local notations
Local notations is a very commonly used tool to express knowledge.- The first use is naming things : we adopt the convention of naming one thing with a particular sound/word.
- The second use is very common in mathematics :
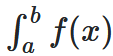 local notations are just the base of modern mathematics.
An example, is how we define the calculation of the surface of an area below a curve :
The notation system uses one symbol
"ʃ"
in conjunction with a 2D layout of other letters.
local notations are just the base of modern mathematics.
An example, is how we define the calculation of the surface of an area below a curve :
The notation system uses one symbol
"ʃ"
in conjunction with a 2D layout of other letters.
SGH documents can embed a third level of language : notations, which apply to all nodes in the document. In fact, icons on nodes carry information on how to how to process automatically nodes :
- Icons help define the language that is used.
- Indications on the importance of nodes . For ex : side note, ignore the node, large comment, etc
One interesting application is the generation of computer prgramms.
- Icons help in defining macros for the extraction processor.
5.2.2. Extracting tables for documents
One important feature from the KM2 processor and the SGH schemes is the capacity to extract sub-tables from tables. One example is the definition or management of projects. Typically a project is made out of WorkPackages (WP), each one having it's own name, deliverables, inputs, start-date, etc (many features, including text and graphics). The project is then a matrix with N WPs and K columns, one for each project attributes. Attributes can be added at any time (for example, we could add 'difficult points', 'competencies', etc). The difficulty is to produce on demand any subtable, consisting of the N WPS and a subset of the features. For example, the planning table will consist only of start and end dates, as well as length and effort.5.3. Computing with SGH schemes
Representing documents from the beginning with graphs allows a huge advantage over linear texts : the structure is always explicit ! Second, there are many existing tree and graph algorithms, the difficulty is to provide a very simple access interface for the casual user.The basic use is the generation of new SGH schemes. This is can be done in several ways :
- Give some words, and generate a SGH according to a model. This is useful for example, to generate a vision of a company, or a scientific domain : the model embodies a structured analysis method.
- Generate a new SGH from many existing SGH.
This is done in a 2-step process :
- Select a set of SGH schemes with the query language.
- Extract the appropriate sub-graphs, using a pattern.
5.4. Some examples of use
The first use of SGH schemes is producing text. This paper was written using SGH schemes and the KM2 post-processor. In fact, the original source document contains 4 different levels of languages :- The text that appears in this file.
- The comments about this text.
- The notations that precise how the document should be understood.
- The macros in python, when some calculation is needed (numbering of paragraphs and production of the summary)
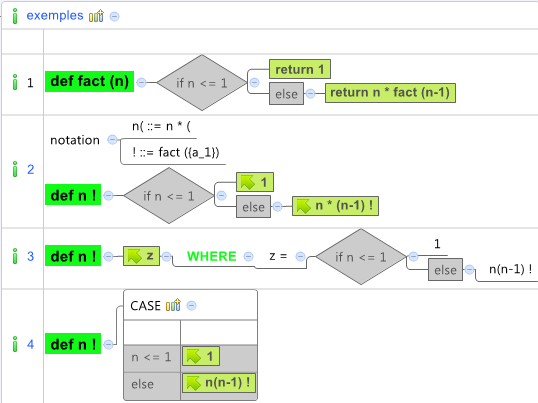
A second important use is the production of programms in many languages, like python, sql, and managing the tests cases : and which compile correctly , once the '!' notation is defined, or even what 'n(' means. Also note that many syntactic variants are available in the KM2 source code, like the 'WHERE' or the 'CASE' with a table shape :.
source code with SGH schemes
|
python code

|
SGH schemes are used effectively for bootstrapping KM2, about 30% of the KM2 code (python) is generated from SGH schemes. One of the most unusual visual extensions is the CASEXY, whicch allows the easy and maintenable expression of embedded 'if's (see example below) , which generates 70 lines of source code :

Some advantages :
- Better use of the screen width programs are usually more than 50% shorter in height, so long programs can fit into a single screen.
- A very important feature is the definition of macros. Macros allow to improve on readability
Another feature of KM2 is the generation of text/documentation for documentation generation. In many technical papers, a lot of tables are written, while many of them contain the same information/labels. For exemple, for a project, we need many tables describing either the planning, or the inputs and outputs, etc each starting with the name of the WorkPackage (WP). Then most of the information and knowledge is split over multiple pages in a document, difficult to read, but also to maintain. For example, adding a WP in many tables is difficult, at least really tedious ! KM2 allows to define a table, that contains all the project data, and then to define what to extract for each sub-table, one by one, thus preventing mistakes. This allows to separate the content of the project, from it's formatted desired output. Once the project has sufficient information, each table is just one-line of SGH scheme.
6. Conclusion
We have shown in this paper that the problem of writing computer programs is a particular case of writing documentation for multiple users and with different languages and levels of languages. The human thought, but also complex systems are highly non linear and need non linear writing systems. Traditional tools are not suitable to handle this complexity, and by force, the vast majority of documents produced are very limited in many ways, in the expression or in the flexibility of use. It is quite sad to note that 60 years after the invention of Lisp, and more than 40 years after the introduction of structured programming, the main programming paradigm of the programming tools is still based on punched card technology and concepts instead of trees and graphs.The SGH schemes allow to capture intrinsically this various aspects of a single document. They are the most general expression of written communication, backed by many studies in cognitive psychology, semiotics and standards of writing systems. The capacity to compute easily with SGH schemes make them very suitable for automated processing and AI tools in a wider sense.
While the challenge of designing a more general and friendly user interface for SGH schemes is still here, we think that we have demonstrated the feasibility of such a tool : the possibilities of the existing interface developed with a very limited effort are already far above most existing tools.
7. Bibliography
- Semiotics
- Umberto Eco
- Paul Otlet Le Livre sur le Livre (book) Les Impressions Nouvelles, 2015.
- Typographs
- Otto Neurath, Book, Neurath Modern Man In The Making 1939 International Foundation for Visual Education
- Languages and writing
- Chinese Language and writing https://en.wikipedia.org/wiki/Written_Chinese
- The nsibidi writing https://en.wikipedia.org/wiki/Nsibidi
- Corean writing http://www.omniglot.com/writing/korean.htm and https://en.wikipedia.org/wiki/Korean_language
- Notations